使用 C++ 来编写高性能的网络服务器程序,从来都不是一件很容易的事情。
为何会这样?因为这类框架提供的都是非阻塞式的、异步的编程接口,异步的编程方式,这需要思维方式的转变。
使用epoll非阻塞式的编程接口让程序结构非常复杂,不易理解
1 | // Event loop |
为什么Go这几年能够大规模流行起来,协程(Goroutine)功不可没,协程非常突出的一点就是它将网络编程API是同步阻塞式的接口,要并发?Go一个协程就好了。
函数调用栈
在讲解协程之前我们需要明确函数调用栈的一些相关概念
首先我们需要明确的是,调用栈是一段连续的地址空间,无论是 caller(调用方)还是 callee(被调用方)都位于这段空间之内。而调用栈中一个函数所占用的地址空间我们称之为「栈帧」(stack frame),调用栈便是由若干个栈帧拼接而成的。一个典型的调用栈模型如下图所示:
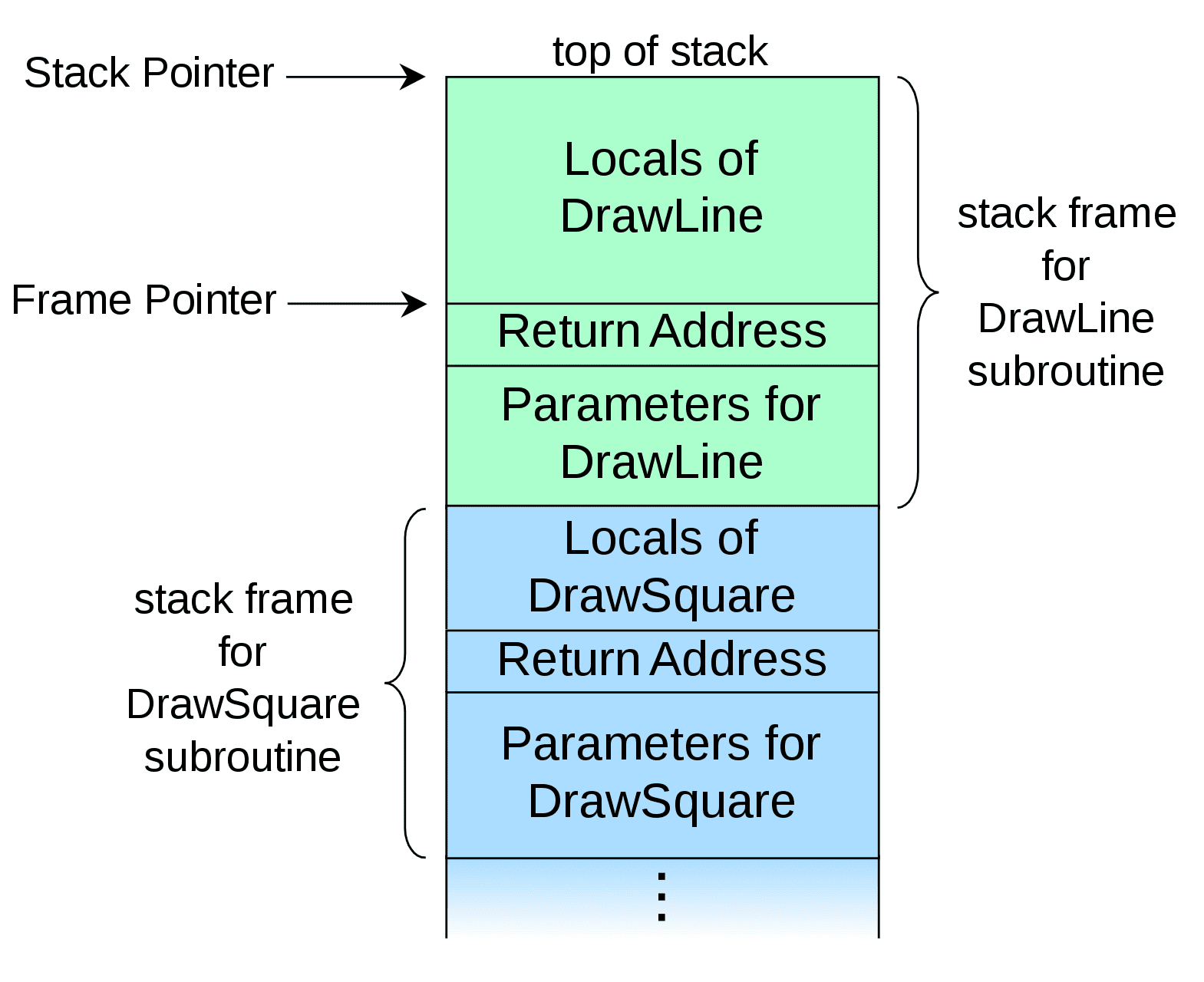
这里的Stack Pointer即栈指针是一个指向当前栈顶部的指针。在 x86 架构中,栈指针由寄存器 esp(Extended Stack Pointer)表示。
这里的Frame Pointer即帧指针是一个指向当前函数栈帧底部的指针。帧指针由寄存器 ebp(Extended Base Pointer)表示。
指令指针是一个指向当前正在执行的指令的指针。指令指针由寄存器 eip(Extended Instruction Pointer)表示。
我们先写一段简单的caller调用callee代码
1 | int callee() { |
汇编代码如下,使用x86-64 gcc 14.1 参数为-m32,采用AT&T语法
1 | callee: |
为什么这里是subl %16, %esp,将栈指针往下移动16个字节,因为在x86平台下,调用栈的地址是从高地址向低地址增长的
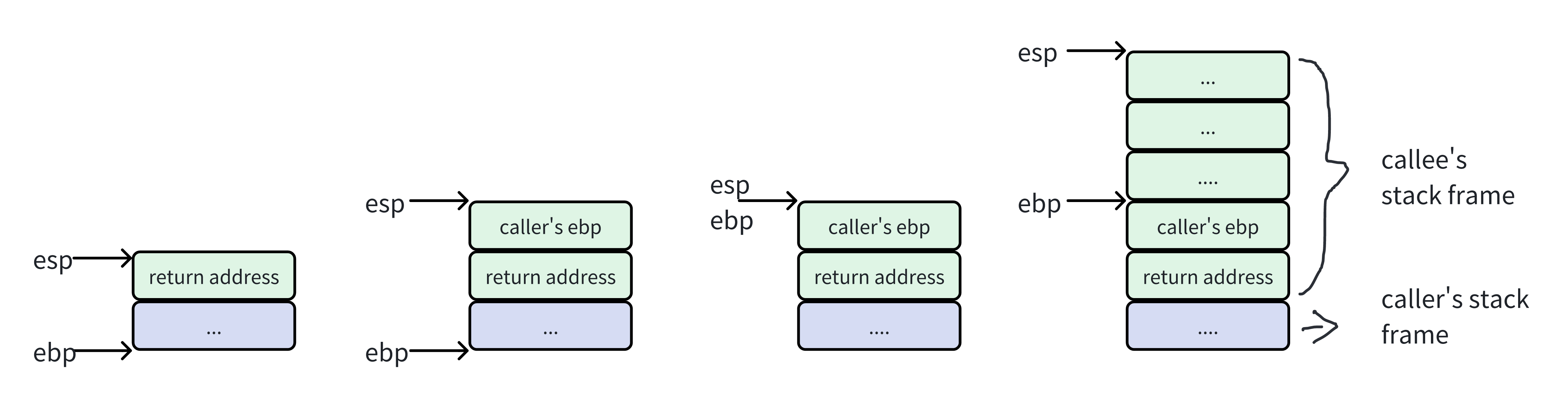
caller调用callee的调用栈变化(忽略传参)
callee返回caller的调用栈变化(忽略传参)
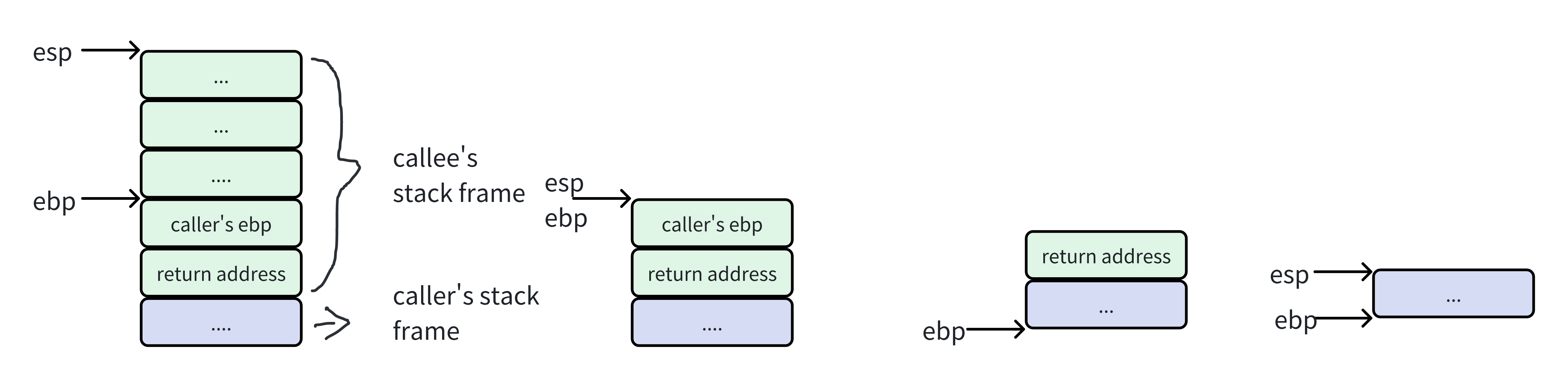
要释放栈帧只需要将栈顶部与callee栈底部对其即可,即movl %ebp, %esp
知道了这一点,我们可以发现实现一个协程的关键点在于如何保存、恢复和切换上下文。已知函数运行在调用栈上;如果将一个函数作为协程,我们很自然地联想到,保存上下文即是保存从这个函数及其嵌套函数的(连续的)栈帧存储的值,以及此时寄存器存储的值;恢复上下文即是将这些值分别重新写入对应的栈帧和寄存器;而切换上下文无非是保存当前正在运行的函数的上下文,恢复下一个将要运行的函数的上下文。有栈协程便是这种朴素思想下的产物。
有栈协程与无栈协程
随着Go语言这几年的大规模流行,协程确实是越来越受到了大家的重视。就连C++也在最新的C++20中原生支持协程。更不用说很多活跃的语言如python,java等,也都是支持协程的。尽管这些协程可能名称不同,甚至用法也不同,但它们都可以被划分为两大类,一类是有(stackful) 协程,例如 goroutine,libco;一类是无栈 (stackless) 协程,例如C++的协程。
所谓的有栈,无栈并不是说这个协程运行的时候有没有栈,而是说协程之间是否存在调用栈(callbackStack)。其实仔细一想即可,但凡是个正在运行的程序,不管你是协程也好,线程也好,怎么可能在运行的时候不使用栈空间呢,调用参数往哪搁,局部变量往哪搁。
⽆栈协程不需要独⽴的执⾏栈来保存协程的上下⽂信息,协程的上下⽂都放到公共内存中,当协程被挂起时, ⽆栈协程会将协程的状态保存在堆上的数据结构中,并将控制权交还给调度器。当协程被恢复时,⽆栈协程会将之 前保存的状态从堆中取出,并从上次挂起的地⽅继续执⾏。协程切换时,使⽤状态机来切换,就不⽤切换对应的上下⽂了,因为都在堆⾥的。⽐有栈协程都要轻量许多。
尽管有栈协程和无栈协程是根据它们存储上下文的机制区分命名的,但我认为二者的本质区别还是在于是否可以在其任意嵌套函数中被挂起。这也决定了有栈协程被挂起时的自由度要比无栈协程高。比如使用无栈协程的 JavaScript 就不能这么写:
1 | async function processArray(array) { |
但使用有栈协程的 Golang 就可以轻松实现类似的逻辑:
1 | func processArray(array []int) { |
这也直接导致了有栈协程在兼容现有的同步代码时异常方便;而无栈协程的兼容性基本为零 —— 总不可能给所有同步代码都加上 async/await 吧,这里其实涉及到了无栈协程关键字的传染性问题,不过就不详细展开了。
对称协程与非对称协程
非对称协程
⾮对称协程,是指协程之间存在类似堆栈的调⽤⽅-被调⽤⽅关系。协程出让调度权的⽬标只能是它的调⽤者。
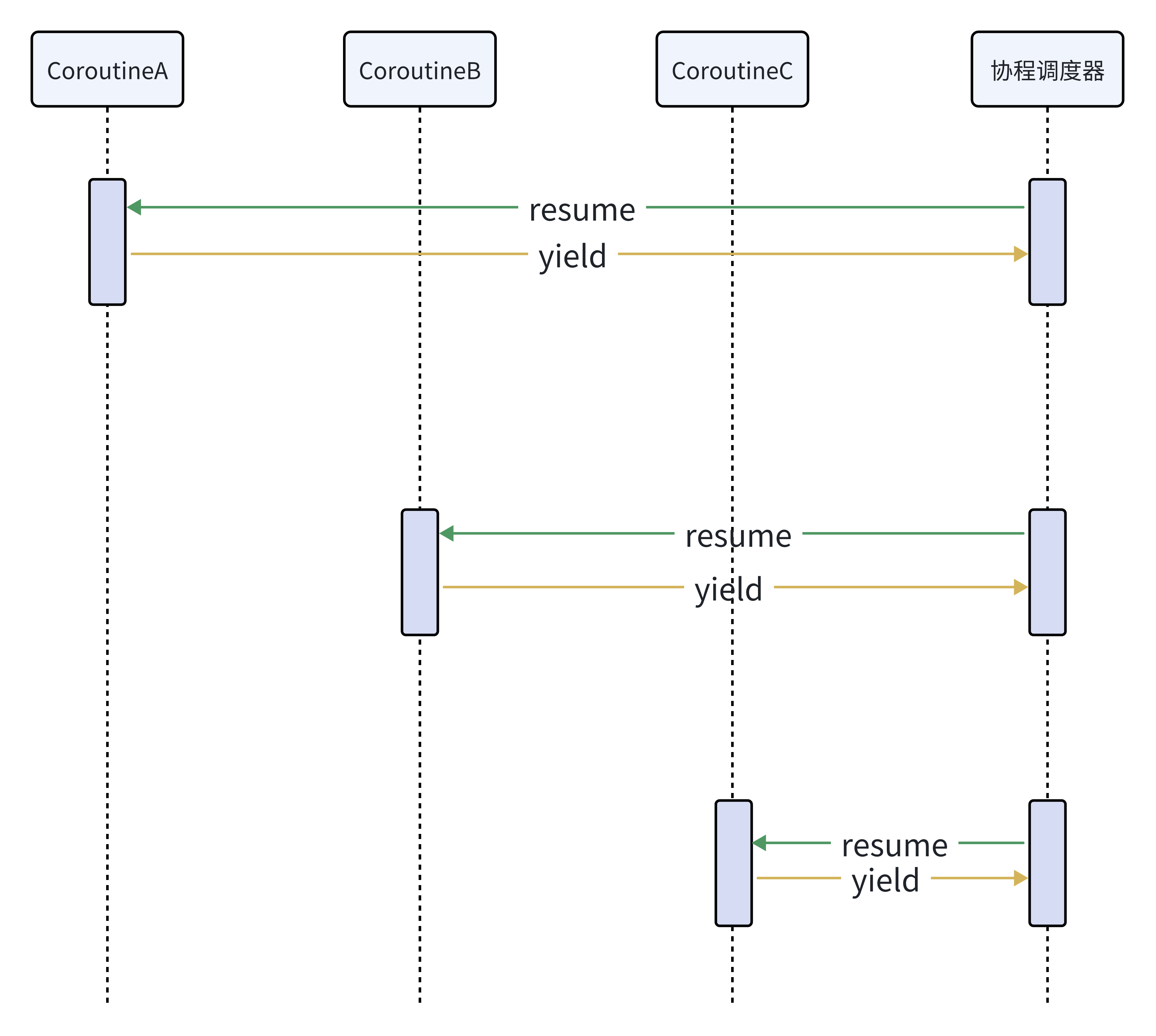
CoroutineA,CoroutineB,CoroutineC之间⽐如与调⽤者成对出现,⽐如resume的调⽤者返回的位置,必须是 被调⽤者yield。
例如这里的CoroutineA只能出让调度权给
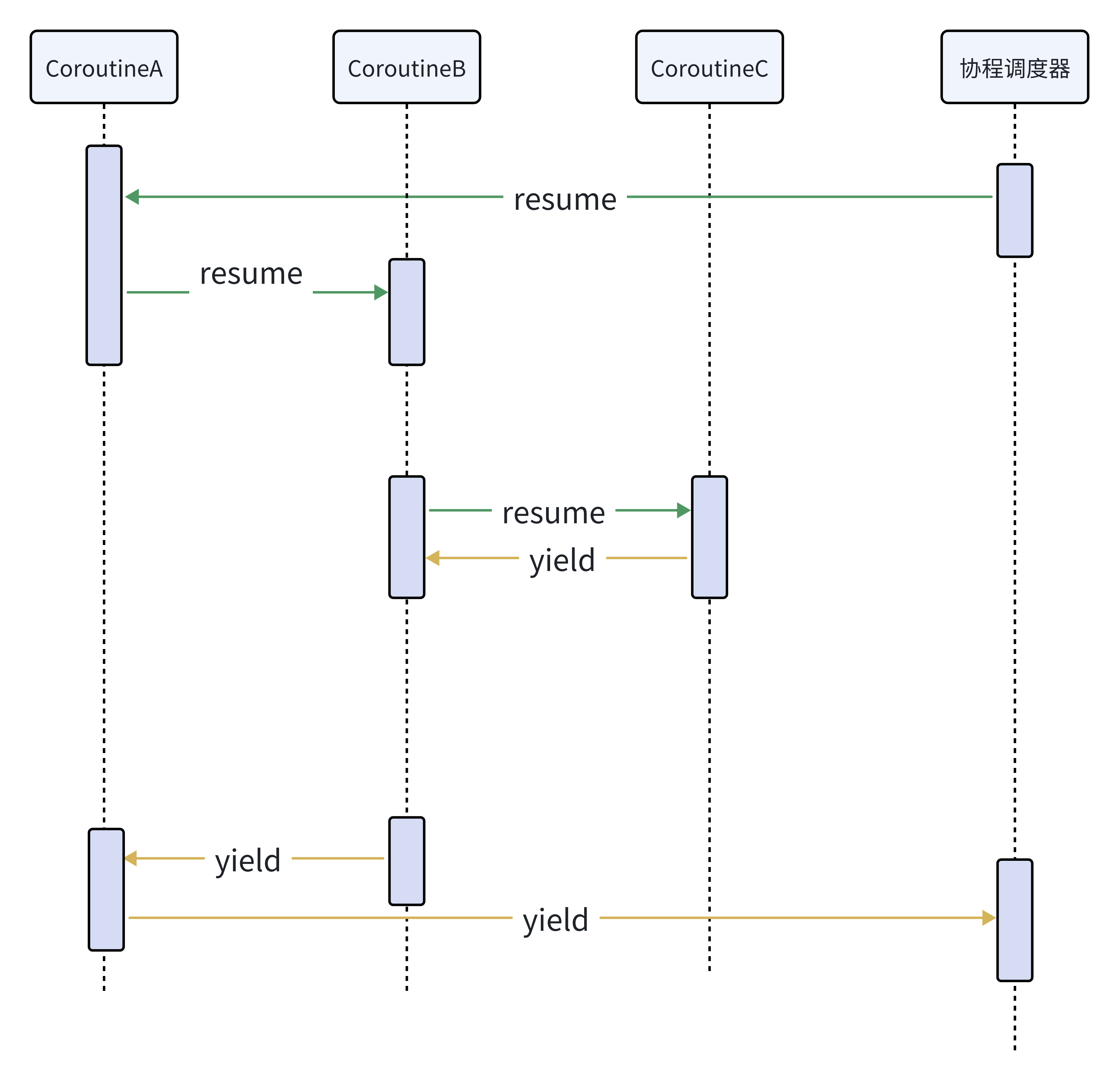
对称协程
对称协程,协程可以不受限制地将控制权交给任何其他协程。任何⼀个协程都是相互独⽴且平等的,调度权可以在 任意协程之间转移。 CoroutineA,CoroutineB,CoroutineC之间是可以通过协程调度器可以切换到任意协程
语言内置的协程并发模式,同步阻塞式的 IO 接口,使得 Golang 网络编程十分容易。那么 C++ 可不可以做到这样呢?
libco案例
接下来,我们结合微信开源的libco库来初步讲解下协程。
libco是一个采用非对称协程,同时也是有栈协程的协程库
我们先来看一个简单的例子:
实例代码来自libco中的example_cond.cpp
生产者和消费者协程
1 | struct stTask_t { |
创建和启动生产者消费者协程
1 | int main() { |
启动这个程序,我们可以发现Producer和Consumer交替打印生产和消费信息
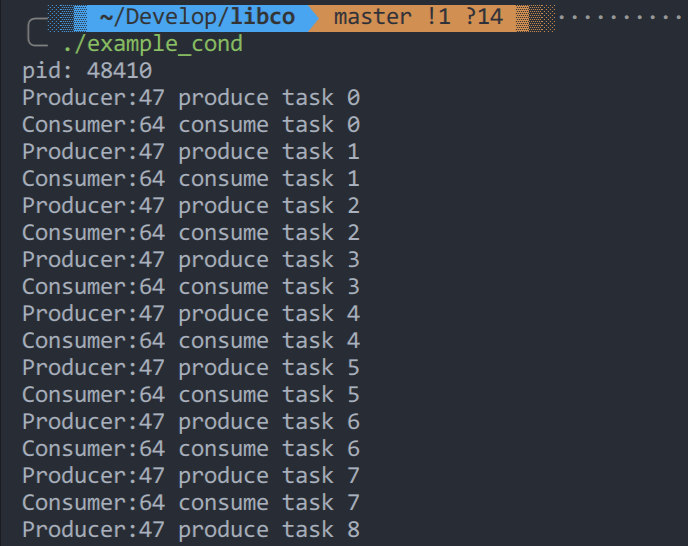
我们启动这个程序的时候使用getpid()打印出程序的pid,然后使用 ps 命令可以神奇的发现它实际上只有一个线程。

还有一个问题。这个程序既然只有一个线程,那么 Producer 与 Consumer 这两个协程函数是怎样做到交替执行的呢?如果熟悉 pthread 和操作系统多线程的原理,应该很快能发现程序里 co_cond_signal()、poll() 和 co_cond_timedwait() 这几个关键点。
libco的协程控制块,stCoRoutine_t
1 | struct stCoRoutine_t |
这里的env和ctx都比较重要,下文会介绍,这里的stack_mem可以看到是固定128KB的大小,但众所周知协程是一个非常轻量级的技术,libco一千万协程并发仅耗内存2.8GB,这是怎么做到的?
这里用到了共享栈的技术:
共享栈本质就是所有的协程在运⾏的时候都使⽤同⼀个栈空间,每次协程切换时要把⾃身⽤的共享栈空间拷⻉。对协程调⽤ yield 的时候,该协程栈内容暂时保存起来,保存的时候需要⽤到多少内存就开辟多少,这样就减少了内存的浪费, resume 该协程的时候,协程之前保存的栈内容,会被重新拷⻉到运⾏时栈中。
协程的stCoRoutineEnv_t 结构体
1 | struct stCoRoutineEnv_t |
这里有个pCallStack和iCallStackSize非常重要,每当启动(resume)一个协程,就将他的协程控制块保存在pCallStack的栈顶,
然后“栈指针”iCallStackSize加1,最后切换context到待启动协程运行。
1 | void co_resume( stCoRoutine_t *co ) |
当协程要让出(yield)CPU 时,就将它的 stCoRoutine_t从
pCallStack 弹出,“栈指针” iCallStackSize 减 1,然后切换 context 到当前栈顶的协程(原来被挂起的调用者)恢复执行。
1 | void co_yield_env( stCoRoutineEnv_t *env ) |

Coroutine2 整处于栈顶,也即是说,当前正在 CPU 上 running 的协程是 coroutine2,正好是curr拿到了当前运行的协程。而 Coroutine2 的调用者是谁呢?
是 Coroutine1,即last拿到了即将运行的协程。当 Coroutine2 让出 CPU 时,只能让给 Coroutine1;如果 Coroutine1 再让出 CPU,那么又回到了主协程的控制流上了,即这里的co_swap(curr, last)交换当前上下文到last即将运行的协程。
根据非对称协程理论,yield 与 resume 是个相对的操作。A 协程 resume 启动了 B 协程,那么只有当 B 协程执行 yield 操作时才会返回到 A 协程。在上一节剖析协程启动函数 co_resume() 时,也提到了该函数内部 co_swap() 会执行被调协程的代码。只有被调协程 yield 让出 CPU,调用者协程的 co_swap() 函数才能返回到原点,即返回到原来 co_resume() 内的位置。
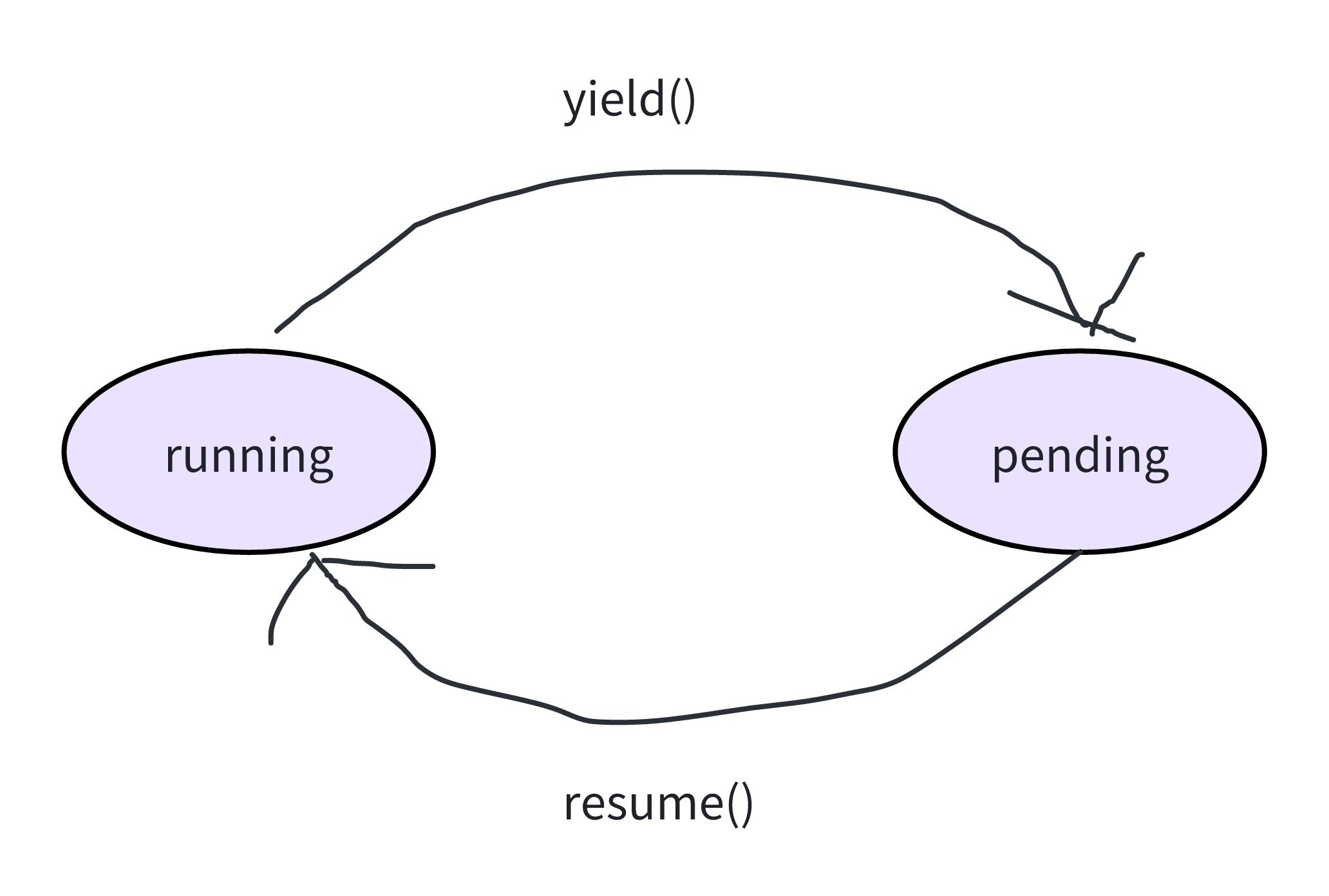
当创建一个协程并调用 resume 之后便进入了 running 状态,之后协程可能通过 yield 让出 CPU,这就进入了 pending 状态。不断在这两个状态间循环往复,直到协程退出,如下图所示:
保存协程执行上下文的coctx_t结构体
1 | struct coctx_t |
coctx_swap的函数原型如下
1 | extern void coctx_swap( coctx_t *,coctx_t* ) asm("coctx_swap"); |
其中,第一个参数为当前协程的 coctx_t 结构指针,其实是个输出参数,函数调用过程中会将当前协程的保存在这个参数指向的内存里;第二个参数即待切入的协程的 coctx_t 指针,是个输入参数, coctx_swap 从这里取上次保存的 context,恢复各寄存器的值。
协程切换的奇妙之处就在这里,调用之前还处于第一个协程的环境,该函数返回后,当前运行的协程就完全是第二个协程了。
那coctx_swap要操作寄存器,那就需要汇编指令了
这里用的是AT&T 语法,为了方便我们只分析x86的汇编指令,x64也是类似的
- **
eax**(Extended Accumulator Register):是一个32位的累加器寄存器,通常用于算术运算和数据传输。 - **
esp**(Extended Stack Pointer):是一个32位的栈指针寄存器,指向当前栈的顶部,用于管理函数调用时的栈帧。
movl 是 AT&T 汇编语法中的一条指令,用于将一个值从源操作数移动到目标操作数。movl 是 mov 指令的 32 位版本,其中 l 表示操作数是 “long” 类型(即 32 位)。
在 AT&T 语法中,movl 的基本格式如下:
1 | movl 源操作数, 目标操作数 |
接下来我们来详细解读下这段汇编
1 | .globl coctx_swap |
至于为什么分别是28,24,20,16... 4,8,12,16...是因为在32位系统下,指针的大小通常是4字节,通过每次偏移四个字节可以依次拿到coctx_t结构体下的regs[1]~regs[6]的位置
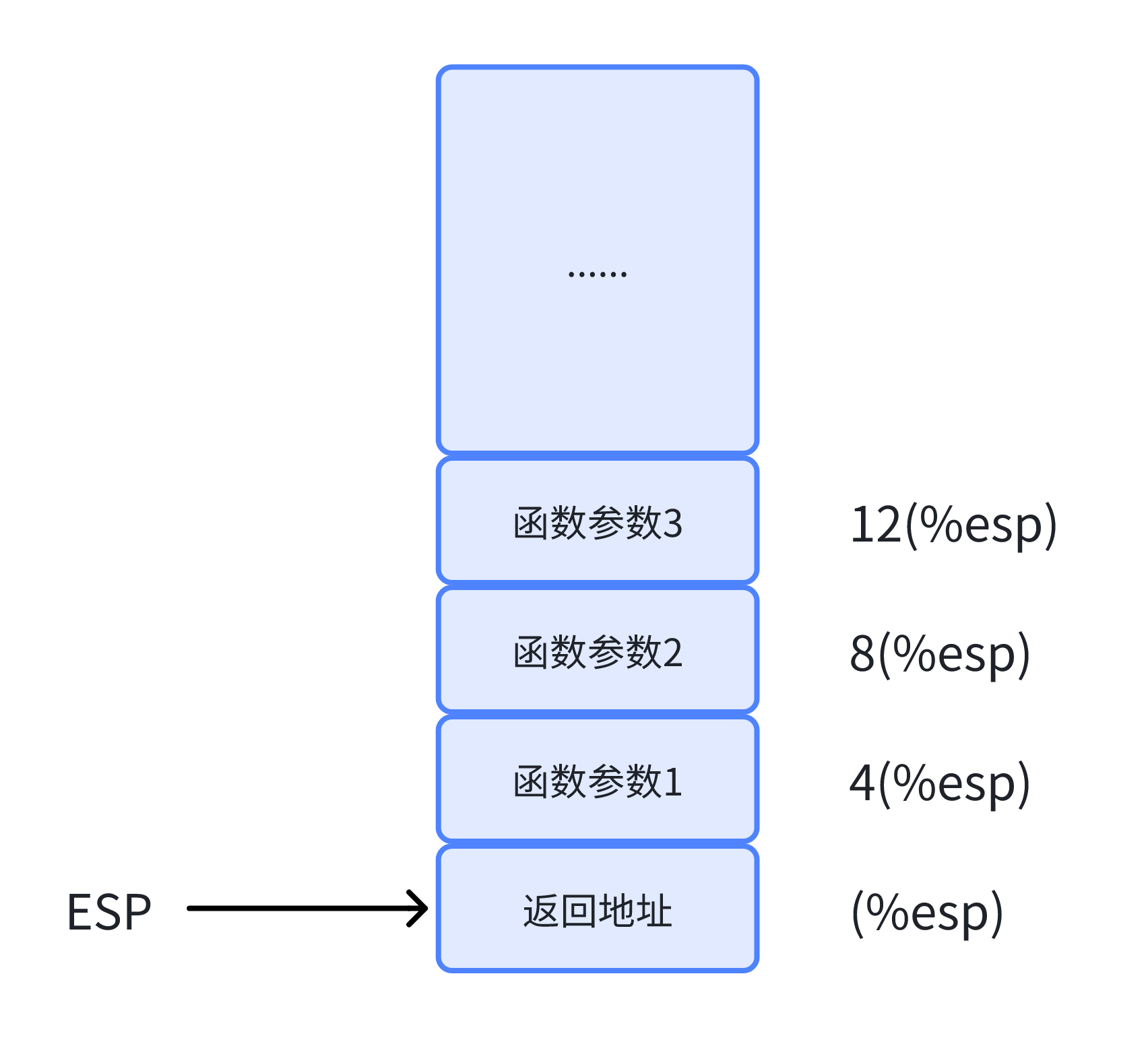
4(%esp)即函数的第一个参数(当前协程context指针),8(%esp)即函数的第二个参数(待切入运行协程的context指针)
我们再来看下libco里的主协程事件循环,分析主协程是如何”调度”工作协程运行的(已略去部分代码):
1 | void co_eventloop(stCoEpoll_t *ctx, pfn_co_eventloop_t pfn, void *arg) |
这里我们使用过epoll非阻塞模型的简直太熟悉了,调用epoll_wait() 等待 I/O 就绪事件,处理就绪的文件描述符。如果用户设置了预处理回调,则调用 pfnPrepare 做预处理;否则直接将就绪事件 item 加入 active 队列。
这里的active实际上是一个链表
1 | struct stTimeoutItemLink_t |
实际上,pfnPrepare() 预处理函数内部也是会将就绪item加入 active 队列,最终都是加入到 active 队列等到行统一处理。
这里我们可以看到遍历active队列,调用工作协程设置的 pfnProcess() 回调函数 resume 挂起的工作协程,处理对应的 I/O 或超时事件。
1 | lp = active->head; |
我们可以看到它周而复始地 epoll_wait(),唤醒挂起的工作协程去处理定时器与 I/O 事件。